
It depends
File and URL datasource: No
When using a File or a URL datasource connected to a CSV file, it's not possible.
Elements Connect does not provide any way to query children CSV files content.
JNDI datasource: Yes
With a JNDI datasource, you can use an open source CSV JDBC driver to query your CSV files: csvjdbc.
The benefits brought by this solution are:
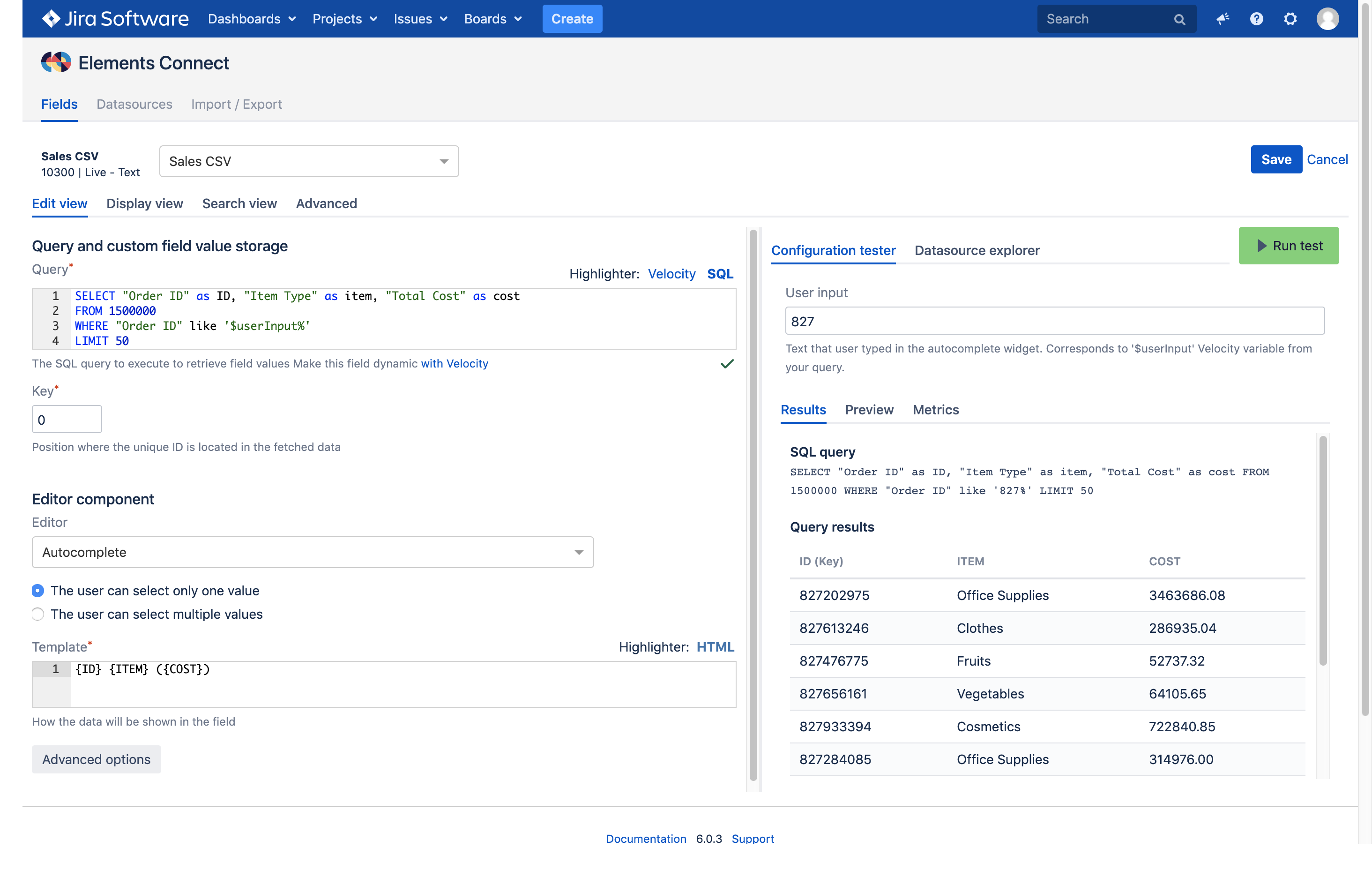
use the power of SQL on your datasource file (WHERE, GROUP BY, ORDER BY, ...)
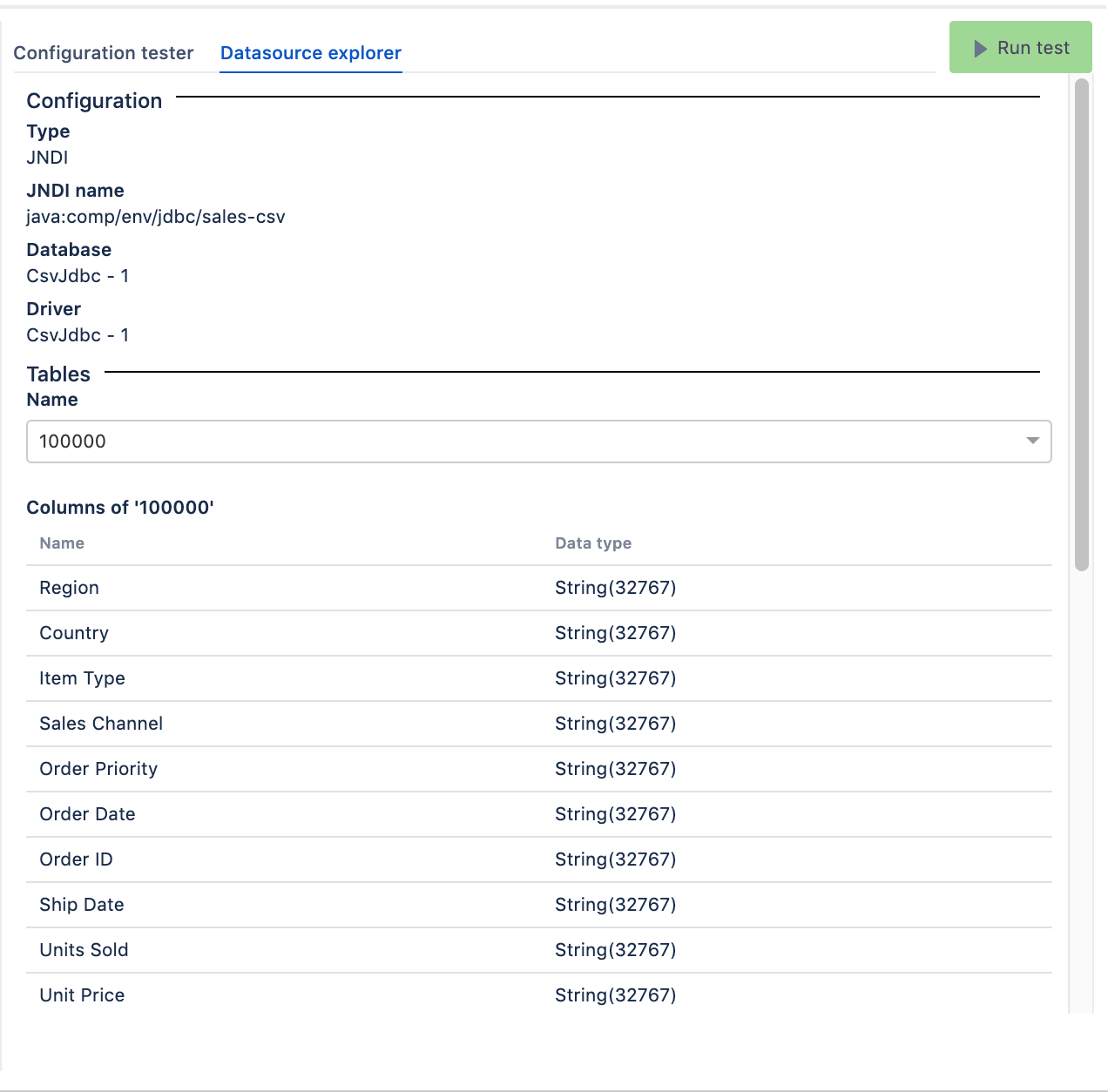
See the structure of your CSV files using the datasource explorer - every file is a distinct table
Performances
While this datasource type requires few configuration steps (no need to configure a database), it shall not be used on very large datasets.
We've made some tests on CSV files with 14 columns, with a Jira 8.2 instance running on a 2016 Macbook Pro with a SSD drive.
The query used for our tests was:
SELECT *
FROM <FILE>
|
# lines |
Average query time |
|---|---|
|
10 |
2 ms |
|
100 |
3 ms |
|
1,000 |
9 ms |
|
5,000 |
50 ms |
|
10,000 |
115 ms |
|
50,000 |
390 ms |
|
100,000 |
741 ms |
|
500,000 |
4000 ms |
|
1,000,000 |
8800 ms |
|
1,500,000 |
13000 ms |
That's a constant average of 9 μs (10-6 sec) per row (except for small files where file opening / closing seems to generate a significant overload)
Configuration
Have a look at the JNDI Datasource page to learn how to configure a CSV SQL datasource.