Improve performances
Table of contents
Depending on the volume of data returned by the datasource and the execution time of the requests, you may experience slowness when editing or displaying issues.
Performance issues can have many causes, but in certain cases changing your configuration can help.
In this section, you'll find hints on how to improve performances.
Configure a display view query
Problem
Imagine that you have a Elements Connect field based on the following SQL request:
| Query | SELECT user_id, username, last_connection_date FROM Users |
| Key | 0 ( the user_id column of the result set) |
| Template | {username} - {last_connection_date} |
When the field is edited, Elements Connect fetches the whole set of users, there are thousands of lines.
When the field is displayed, Elements Connect executes the same request again and tries to match the user_id column with the value(s) stored in your field.
This takes the same amount of time to display the field. And this happens any time someone displays an issue.
Solution
When the field is displayed, it is not needed to get the entire set of users to only display one record.
The solution is to configure a specific display query that only retrieves the value selected on display using the $currentCustomfieldValue variable (see Velocity).
Display query
SELECT username, last_connection_date FROM Users WHERE user_id = $currentCustomfieldValue
This request will return instantly with one result (especially if you have an index on the user_id) and will be faster than the edit query.
Use the autocomplete editor and $userInput
Problem
Generally, the autocomplete is used when there is in a large amount of options to display. The autocomplete allows the user to input text to filter the results.
This is convenient on the browser side, but this means that you have a large amount of data in your datasource too. Your field can take time to load.
Imagine that you have a Elements Connect field based on the following SQL request:
| Query | SELECT user_id, username FROM Users |
| Key | 0 ( the user_id column of the result set) |
| Template | {username} |
This query returned 100,000s of results.
Instead of loading the whole issues list, we would like to limit the issues returned to what the user typed.
We need to change a few things in your field configuration
Solution
The $userInput Velocity variable is available for use in your query. It contains what the user typed in the autocomplete.
When this variable is used in the query, the autocomplete will execute the query every time the user types something different.
If you do not use $userInput in your query, the field will only fetch the results once and filter them locally.
Change your edit query like this:
SELECT user_id, username FROM Users WHERE username like '%$userInput%' LIMIT 15
That way, only the first 15 users matching the user input will be retrieved from the datasource.
Troubleshooting
Don't execute useless queries with $query.abort()
Problem
Imagine that have two fields Company and Contact. The contact depends on the company but does not make sense if company is not set.
Company configuration (field id: 10001)
| Query | SELECT id, name FROM Companies |
| Key | 0 ( the id column of the result set) |
| Template | {name} |
Contact configuration
| Query | SELECT id, name FROM Contact WHERE company_id = $issue.customfield_10001 |
| Key | 0 ( the id column of the result set) |
| Template | {name} |
The Contact field request is executed every time, even if the company is not set. This will certainly return an empty list and nothing is displayed in the field.
From the end user, this is ok, but this would be far better if we could avoid making a useless request to the server.
This is where $query.abort() enters the scene.
Solution
If we change the last query to this:
#if(!$issue.customfield_10001 || $issue.customfield_10001.length() == 0)
$query.abort()
#end
SELECT id, name
FROM Contact
WHERE company_id = $issue.customfield_10001
When the Company (customfield_10001) is unknown or empty, the request evaluation encounters the $query.abort() statement.
In this case, the request process is stopped and an empty result is returned.
This works exactly as if the request returned no result, but the useless request to the datasource is avoided.
This is particularly helpful when you have a lot of depending fields.
![]() For more information on this topic, please read the following documentation: How to use variables in a Connect field query
For more information on this topic, please read the following documentation: How to use variables in a Connect field query
Enable Elements Connect cache
Enabling the cache can help with performances when you use the same requests a lot during a short period of time.
The cache cannot be enabled for JQL datasource. JQL search is already optimised in Jira and adding a cache would not help.
How does it work ?
The cache stores the result of a request to a datasource for a certain amount of time. If during this time the exact same request is made again, then the result previously stored is returned instead of calling the datasource again.
You can enable the cache in every field advanced configuration.
![]() The cache is stored in memory.
The cache is stored in memory.
Do I need to enable it ?
Enabling the cache has advantages as it lowers the number of requests made to a datasource and allows a faster resolution of a field content.
But this also comes with a cost : The cache consumes memory and the results from the cache might not be up to date compared to the datasource.
You should enable the cache if
- The same request is used in many fields
- Your datasource is slow to answer because of a network latency or because it is undersized compared to your needs
You should not enable the cache if
- Your requests return large results (e.g. millions of SQL rows). In this case, the memory consumption in your Jira could increase a lot
- You need up to date data. This is further discussed in cache duration below. Data in your cache might be obsolete compared to your datasource.
What value for the cache duration ?
The cache duration tells how long a request result is kept in memory. Past this time, the memory is freed and if the same request happens again, then the datasource is called (and the cache populated again)
The minimum cache duration is 1 second.
This is hard to tell exactly what value you need for your configuration, but here are three different examples that can help you guess:
You have many fields with the same query on every issues
| Context | you configure a lot of read-only fields displaying different information based on the same request. |
|---|---|
| Recommended duration | 15s |
| Explanation | All identical queries will happen during the same call when displaying the issue. A cache of 15s should be enough to avoid many times the same query and to have up to date data. |
| Expected gain | If you have 5 fields, then you can save 4 requests. |
Your Jira is loaded and you have many users watching different issues at the same time
| Context | Relatively loaded platform. |
|---|---|
| Recommended duration | 10m |
| Explanation | Having a cache of 10 minutes on your fields theoretically avoids redundant requests for 10 minutes. If you don't need up to date data at the minute, using this value could save a lot of datasource requests. |
| Expected gain | Any time someone displays an issue with 5 Elements Connect fields, you'll have 5 peak requests to the datasource. Having a cache of 10 minutes can limit the calls to once for each different request every 10 minutes. |
Your datasource is updated at night only
| Context | Datasource is updated at night (3AM) and you don't need up to date data. |
|---|---|
| Recommended duration | 1h |
| Explanation | As your data only change at night, you can keep results in memory if not too large. 1 hour allows cleanup of memory when not used. |
| Expected gain | In this case, you will have at most one (different) request to the datasource every hour. |
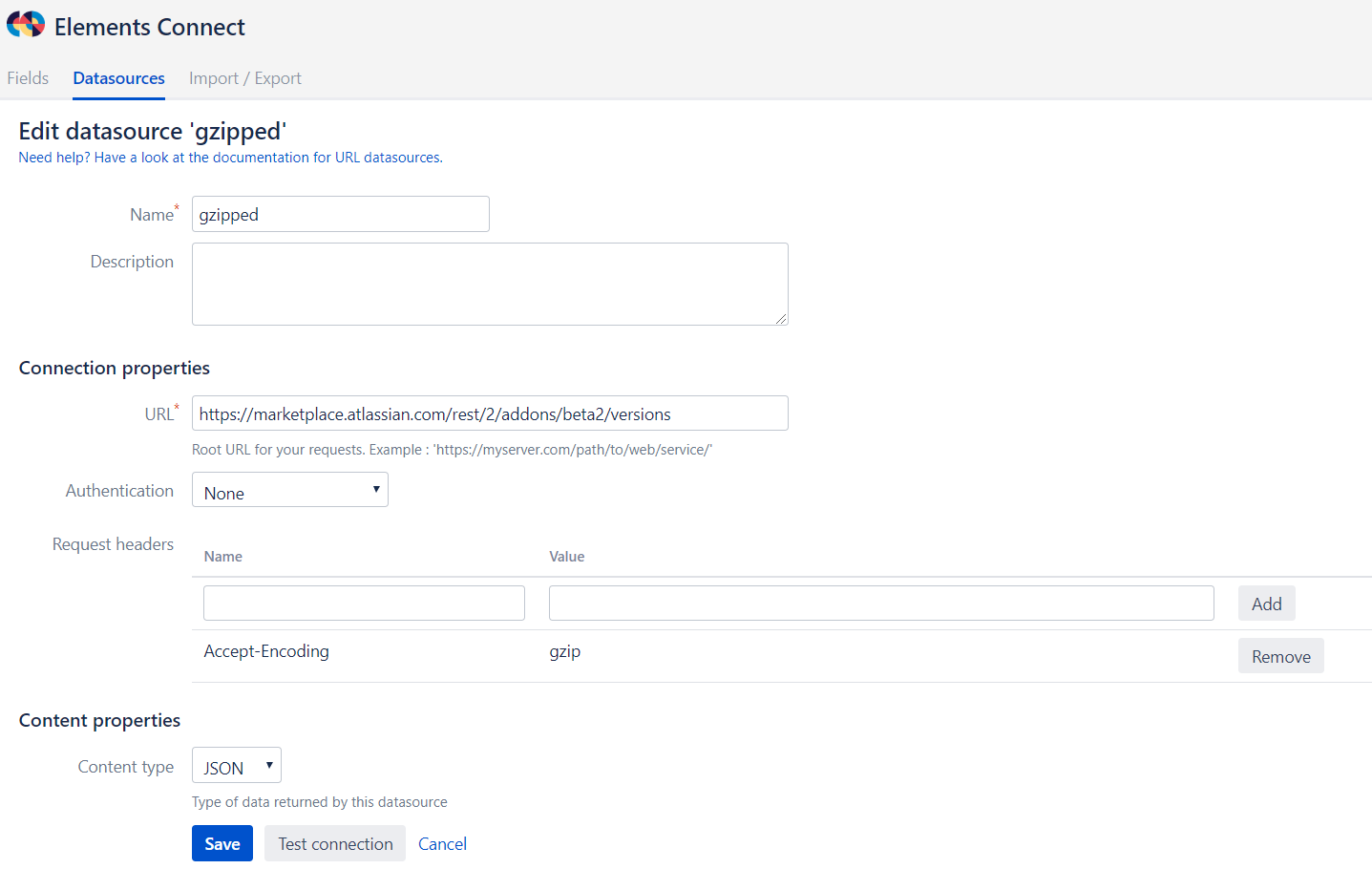
Enable gzip compression for URL datasources
Problem
Sometimes when making HTTP calls, the server response size may considerably degrade response times due to large volume of data. Elements Connect fields and Jira pages may seem slow and unresponsive.
Solution
To improve performances, some servers can handle gzip compression before sending content which may drastically reduce response times. To tell the server to compress data with gzip, HTTP protocol proposes a standard way which may be easilly specified in an Elements Connect datasource configuration: add an Accept-Encoding header with gzip value.
You should explicitely use gzip compression if
- The server handles gzip responses
- You expect responses with large datasets
- Your datasource uses a basic or no authentication (for datasources using OAuth gzip is already handled out of the box!)